Neural Network Tutorials - Herong's Tutorial Examples - v1.22, by Herong Yang
What Is RNN (Recurrent Neural Network)
This section provides a quick introduction of RNN (Recurrent Neural Network). It starts from a generic neural network hidden layer, and slowly converts it into a RNN layer by combining the weighted average with the activation function into a recursive function to manage a feed from one sample to the next sample recursively.
What Is RNN (Recurrent Neural Network)? RNN is an extension of the traditional neural network, where hidden layers are taking extra feeds from the same layer left the previous sample.
Those extra feeds make the output being depended on not only from the current sample, but also from the previous sample. Because of this feature, RNN works better than the traditional neural network on sample datasets where samples have some impacts on subsequent samples. For example, words in an novel.
If you have a good understanding of traditional neural network models, you can follow this tutorial to learn the basic architecture of RNN models.
1. Take a standard illustration of a traditional neural network model.
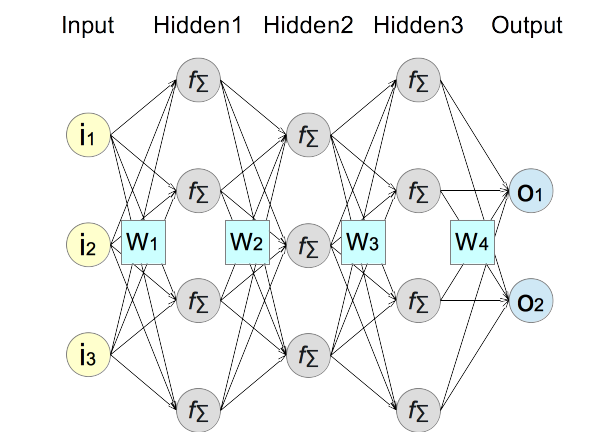
2. Zoom in on hidden layer #2 by hiding other layers to change it towards a generic NN (Neural Network) layer. Input values of the layer are represented as x1, x2, x3, x4. Output values of the layer are represented as y1, y2, y3 as its output. The weight matrix W2 is renamed to W to be more general.
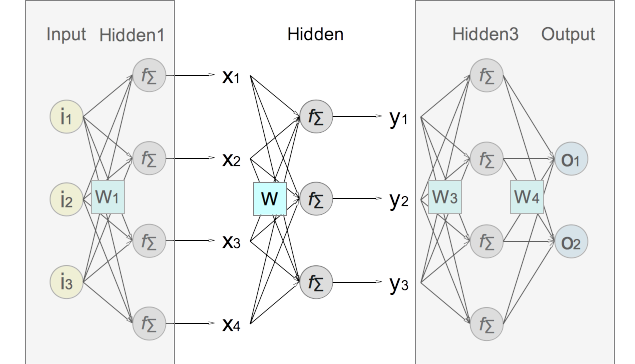
3. The formula of the forward calculation that generates the output from the input for a generic NN (Neural Network) layer can be expressed as:
NN forward calculation on a generic layer: y1 = f(∑(W1,j*xj)) y2 = f(∑(W2,j*xj)) y3 = f(∑(W3,j*xj)) ∑() represents the weighted average of input values calculated as the dot product (or inner product) of one row from the weight matrix and the input vector. f() represents the activation function (the logistic sigmoid function for example)
4. Now condense all nodes in the generic layer as a sing element, using x to represent the input vector (input values as its elements), y to represent the output vector (output values as it members), and W to represent the weight matrix. Note that this condensed diagram is valid for all hidden and output layers.
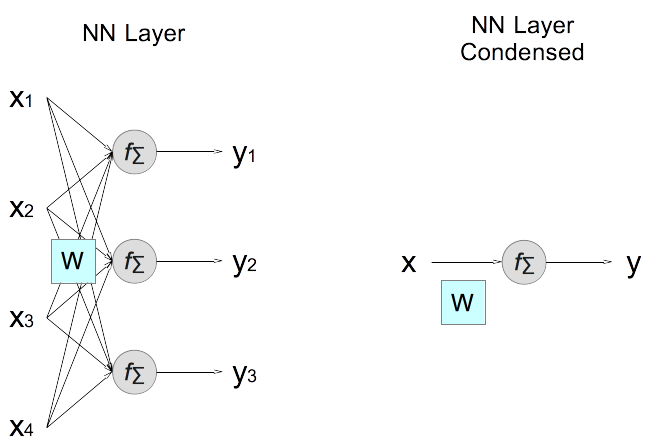
5. Condense also the expression the forward calculation.
NN forward calculation on a generic layer condensed: y = f(W·x) · represents the dot operation of a matrix and a vector.
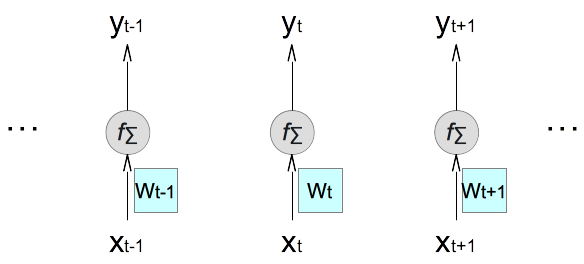
6. If the NN model is applied to a sequence of samples, (..., xt-1, xt, xt+1, ...), the condensed diagram can be rotated and replicated to illustrate forward calculations of the same layer on multiple sequential samples. It shows that forward calculations on different samples are independent from each other in a traditional neural network model. Note that the weight matrix is updated after each sample during the training phase. This is why it is labeled differently for different sample.
7. Now we are ready to extend the traditional neural network into a recurrent neural network by replacing the combination of activation function f() and the weighted average operation ∑() a recursive function R() that takes two inputs and generate two outputs. One output, called y, goes to the layer and the other output, called s, stays in the same layer and is used as an input the next sample.
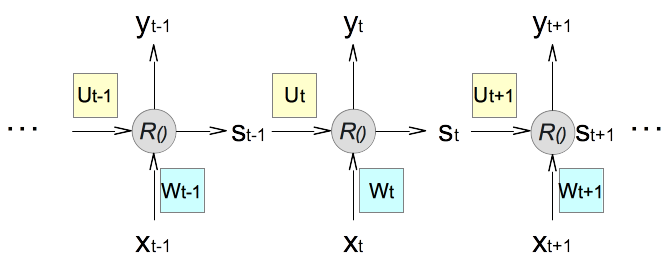
8. If we focus on the forward calculation of a single sample, xt, in a sequence of samples, we can express the recursive function R() as:
(yt, st) = R(xt, Wt, st-1, Ut) Inputs: xt represents the input vector of the current sample. Wt represents the weight matrix on the input vector for the current sample. st-1 represents the state vector generated from the calculation of the previous sample. The state vector is introduced in RNN to feed information from one sample to the next sample. Ut represents the weight matrix on the state vector for the current sample. Outputs: yt represents the output vector of the current sample. st represents the state vector to feed information to the next sample.
9. If you like a more compact format, we can illustrate the RNN layer architecture with a single component, also called a RNN cell, with a circular arrow to represent its recursive nature. The state vector is omitted.
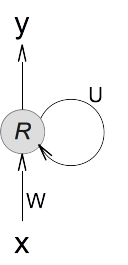
Hope you have a good understanding on how information flows in a neural network layer in a RNN model now. What's left is how to construct the recursive function R(), which will be discussed in the next tutorial.
Table of Contents
Deep Playground for Classical Neural Networks
Building Neural Networks with Python
Simple Example of Neural Networks
TensorFlow - Machine Learning Platform
PyTorch - Machine Learning Platform
CNN (Convolutional Neural Network)
►RNN (Recurrent Neural Network)
►What Is RNN (Recurrent Neural Network)
What Is LSTM (Long Short-Term Memory)
What Is GRU (Gated Recurrent Unit)
GAN (Generative Adversarial Network)