Neural Network Tutorials - Herong's Tutorial Examples - v1.22, by Herong Yang
What Is LSTM (Long Short-Term Memory)
This section provides a quick introduction of LSTM (Long Short-Term Memory) recurrent neural network model. LSTM uses two state vectors, s representing the short-term memory and l representing long-term memory, to resolve the vanishing gradient problem in the standard recurrent neural network model.
What Is LSTM (Long Short-Term Memory)? LSTM, introduced in 1997 by Sepp Hochreiter and Jürgen Schmidhube, is an enhancement of the RNN (Recurrent Neural Network) to resolve the vanishing gradient problem.
In order to enhance the capability of the neural network cell, LSTM uses two state vectors, s representing the short-term memory and l representing long-term memory, as described in this tutorial.
1. If we continue with our compact format of the RNN layer architecture, the LSTM layer architecture, which is a 2-state recursive neural network layer, can be illustrated as the following.
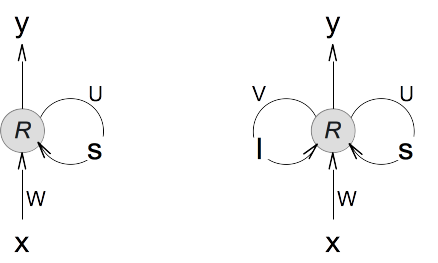
2. If unfold the RNN layer architecture, using (..., t-1, t, t+1, ...) to represent the sample sequence, we will have:
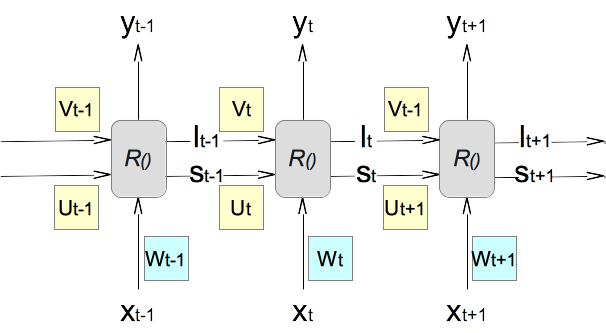
3. Now the recursive function R() for a LSTM Layer can be expressed as the following.
(yt, st, lt) = R(xt, Wt, st-1, Ut, lt-1, Vt) Inputs: xt represents the input vector of the current sample. Wt represents the weight matrix on the input vector for the current sample. st-1 represents the short-term memory state vector generated from the calculation of the previous sample. Ut represents the weight matrix on the short-term memory state vector for the current sample. lt-1 represents the long-term memory state vector generated from the calculation of the previous sample. Vt represents the weight matrix on the long-term memory state vector for the current sample. Outputs: yt represents the output vector of the current sample. st represents the short-term memory state vector to feed information to the next sample. lt represents the long-term memory state vector to feed information to the next sample.
4. One popular way of constructing the recursive function R() is to use gate functions to control the flow of information from inputs to outputs. A gate function is a pointwise multiplication of a gate vector of values in the range of (0.0, 1.0) and the targeted information vector. A gate function acts like a switch. The targeted information will pass through, if the switch is on (gate vector of 1). The targeted information will be stoped, if the switch is off (gate vector of 0). Mathematically, a gate function G() for vectors of n elements can be expressed as:
|g1| * |i1| |g1*i1|
|g2| * |i2| |g2*i2|
G() = g * i = |g3| * |i3| = |g3*i3|
|g.| * |i.| |g.*i.|
|gn| * |in| |gn*in|
g represents the gate vector
i represents the target information vector
5. The standard LSTM architecture splits the recursive function R() into two parts, input part Ri() and the output part Ro(). Then 3 gate functions, forget gate Gf(), input gate Gi(), output gate Go(), are added to control the flow of information. Weight matrices are re-distributed into partial recursive functions and gate functions. The result is shown on the right side of the diagram below:
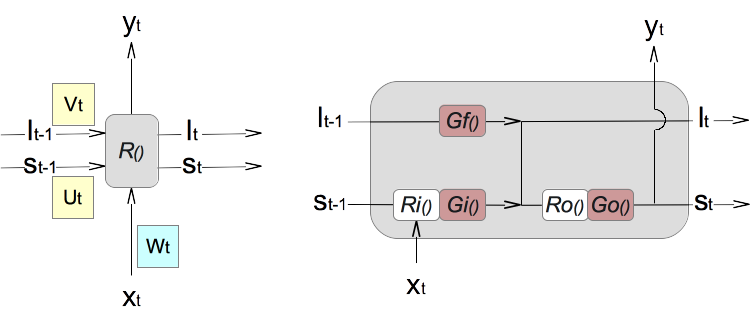
6. Now we have some options to construct partial recursive functions and gate functions. One of them is commonly used and can be expressed below using 3 gate vectors as temporary variables:
Forget gate vector: f = sigmoid(Wgft · xt + Ugft · st-1) Input gate vector: i = sigmoid(Wgit · xt + Ugit · st-1) Output gate vector: o = sigmoid(Wgot · xt + Ugot · st-1) Forget gate function: Gf() = f * lt-1 Input part of recursive function: Ri() = tanh(Wt·xt + Ut·st-1) Input gate function: Gi() = i * Ri() = i * tanh(Wit·xt + Uit·st-1) Long-term memory vector: lt = Gf() + Gi() = f * lt-1 + i * tanh(Wit·xt + Uit·st-1) Output part of recursive function: Ro() = tanh(lt) Output gate function: Go() = o * Ro() = o * tanh(lt) Short-term memory vector: st = Go() = o * tanh(lt) Output of the layer: yt = st() = o * tanh(lt) Where: · represents the dot operation of a matrix and a vector. * represents pointwise multiplication to two vectors. Wgft, Wgit, and Wgit represent weight matrices on xt. Ugft, Ugit, and Ugit represent weight matrices on st-1. Vt representing weight matrices on lt-1 is not used.
7. If you like matrix format, the LSTM mathematical model can be written as:

8. The above LSTM mathematical model can be illustrated graphically as the diagram below:
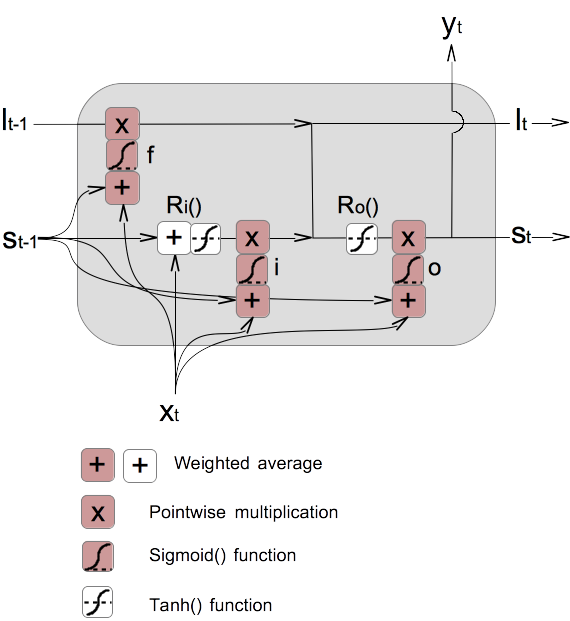
9. If we look at those gate vectors are calculated again, they are actually RNN layers themselves. They follow the same forward calculation pattern as the standard RNN layer:
Standard RNN forward calculation pattern: yt = sigmoid(Wt·xt + Ut·st-1) st = yt
10. The following diagram shows 4 RNN layers inside the common LSTM model.
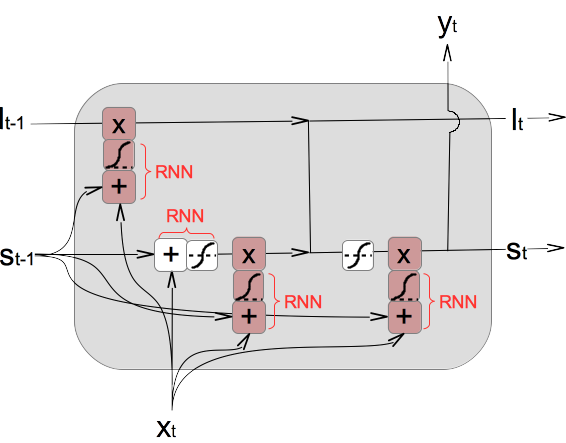
11. Of course, the common LSTM model can be illustrated differently. Here are some examples I have collected from the Internet.
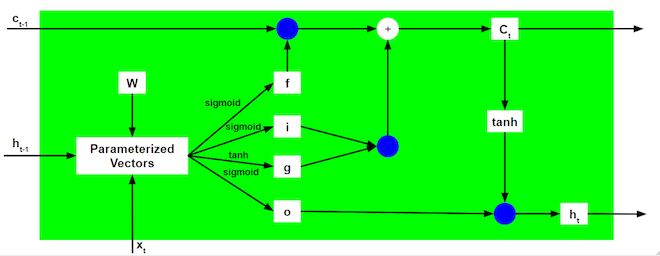
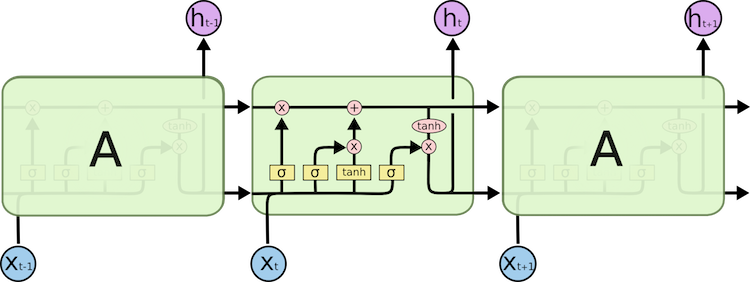
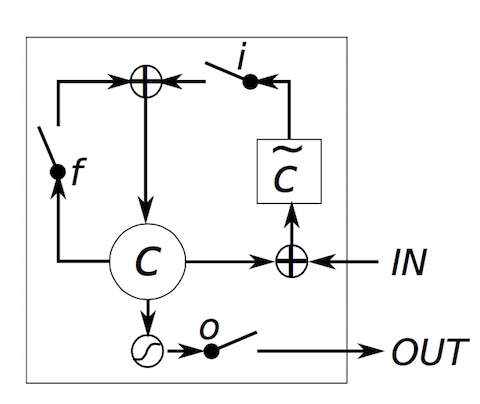
Table of Contents
Deep Playground for Classical Neural Networks
Building Neural Networks with Python
Simple Example of Neural Networks
TensorFlow - Machine Learning Platform
PyTorch - Machine Learning Platform
CNN (Convolutional Neural Network)
►RNN (Recurrent Neural Network)
What Is RNN (Recurrent Neural Network)
►What Is LSTM (Long Short-Term Memory)
What Is GRU (Gated Recurrent Unit)
GAN (Generative Adversarial Network)