Neural Network Tutorials - Herong's Tutorial Examples - v1.22, by Herong Yang
What Is GRU (Gated Recurrent Unit)
This section provides a quick introduction of GRU (Gated Recurrent Unit), which is a simplified version of the LSTM (Long Short-Term Memory) recurrent neural network model. GRU uses only one state vector and two gate vectors, reset gate and update gate.
What Is GRU (Gated Recurrent Unit)? GRU is a simplified version of the LSTM (Long Short-Term Memory) recurrent neural network model. GRU uses only one state vector and two gate vectors, reset gate and update gate, as described in this tutorial.
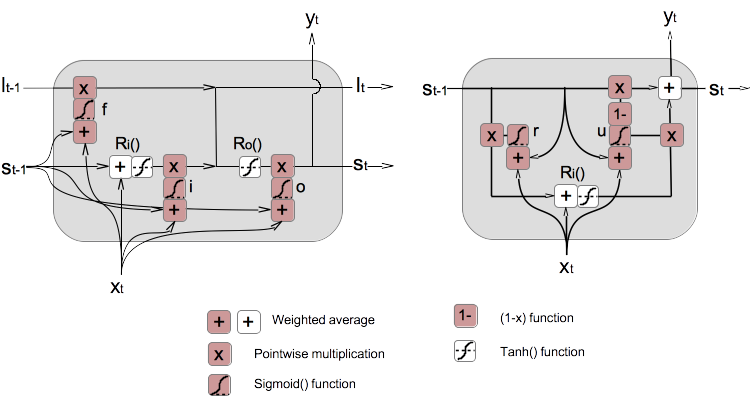
1. If we follow the same presentation style as the lSTM model used in the previous tutorial, we can present the GRU model as information flow diagram as shown below (on the right).
2. Similar to the LSTM model, the reset gate vector and the update gate vector are calculated as below.
Reset gate vector: r = sigmoid(Wgrt · xt + Ugrt · st-1) Update gate vector: u = sigmoid(Wgut · xt + Ugut · st-1)
3. Note that reset gate vector, r, creates only one gate function to control the flow of st-1 into the input recursive function Ri(). But the update gate vector, u, creates a pair of gate functions to control the flow of st-1 and Ri() into final outputs, st and yt.
4. The RGU model can also be expressed in matrix format as shown below.
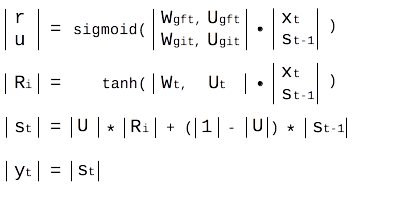
5. If you are reading other GRU documentations, you may see different presentations of the GRU model. Some examples are listed below.
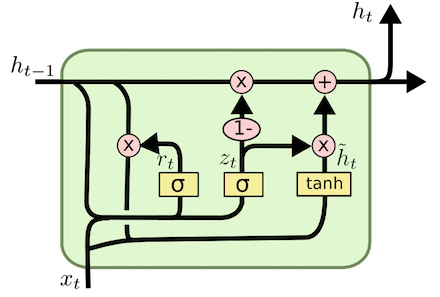
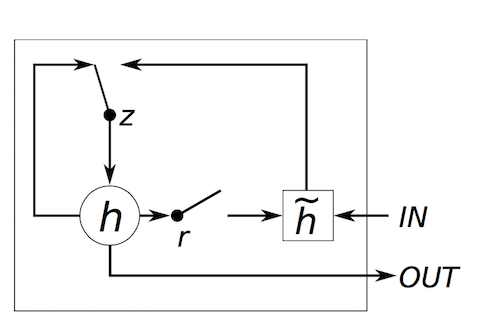
Table of Contents
Deep Playground for Classical Neural Networks
Building Neural Networks with Python
Simple Example of Neural Networks
TensorFlow - Machine Learning Platform
PyTorch - Machine Learning Platform
CNN (Convolutional Neural Network)
►RNN (Recurrent Neural Network)
What Is RNN (Recurrent Neural Network)
What Is LSTM (Long Short-Term Memory)
►What Is GRU (Gated Recurrent Unit)
GAN (Generative Adversarial Network)